
Transformations SQL et Python
Dans les blogs précédents, nous avons présenté comment mettre en place un datalakehouse basé sur le moteur duckdb et le stockage de fichiers S3. Nous avons également montrer qu’il était ensuite très facile de définir des transformations SQL au sein de ce datalake grace à l’outil DBT intégré à la plateforme datatask.
Cette approche très flexible permet de répondre à un très grand nombre de besoins en termes de transformations mais comment peut-on gérer des transformations plus complexes qui ne peuvent pas être traitées en SQL ? C’est ce que nous allons voir dans ce post
Transformation de données par script python
Le langage python s’est imposé depuis quelques années comme une référence pour la le traitement de la donnée. Qu’il s’agisse de traitements simples comme le nettoyage d’un dataset ou bien plus élaborés tels que l’enrichissement de données, le machine learning ou dernièrement l’IA générative.
La plateforme datatask permet de mettre en production très simplement des scripts python de transformation de données à travers la notion d’artefact. Ce dernier est d’une part d’un conteneur contenant le code python et ses dépendances et d’autre part de l’ensemble des paramètres d’exécutions. Cet artefact peut ensuite être exécuté à travers l’instantiation d’une tâche déclenchée manuellement ou programmée.
L’exemple suivant correspond à la définition de l’artefact crypto-transform (le code étant stocké dans un repository git):
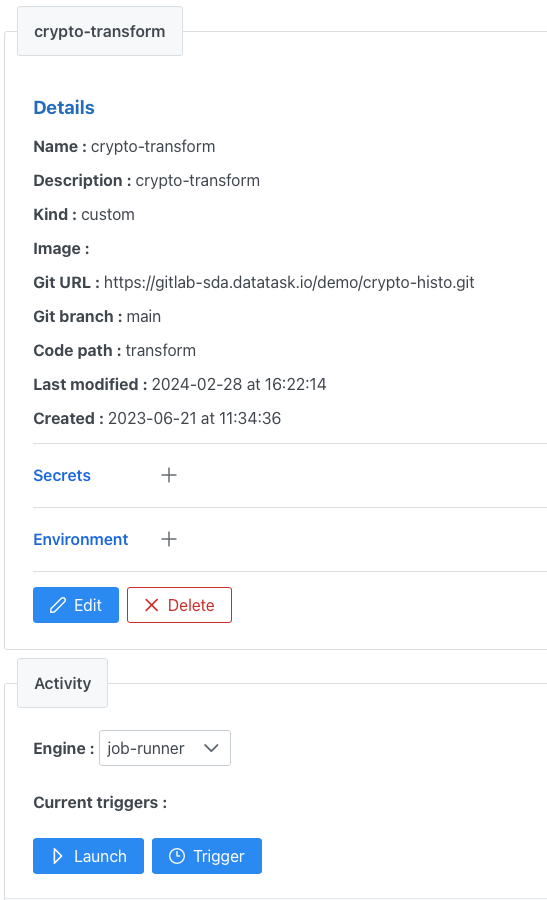
Il est alors possible d’enchainer des transformations SQL via DBT (voir post précédent) et des transformations python à l’aide du mécanisme de bundle de datatask (un bundle est défini par un enchainement de tâches séquentielles ou parallèles).
Ci-dessous l’exemple d’un bundle composé d’une tâche de transformation DBT top25_cryptbtc_s3 suivi de la tâche de transformation python précédente :
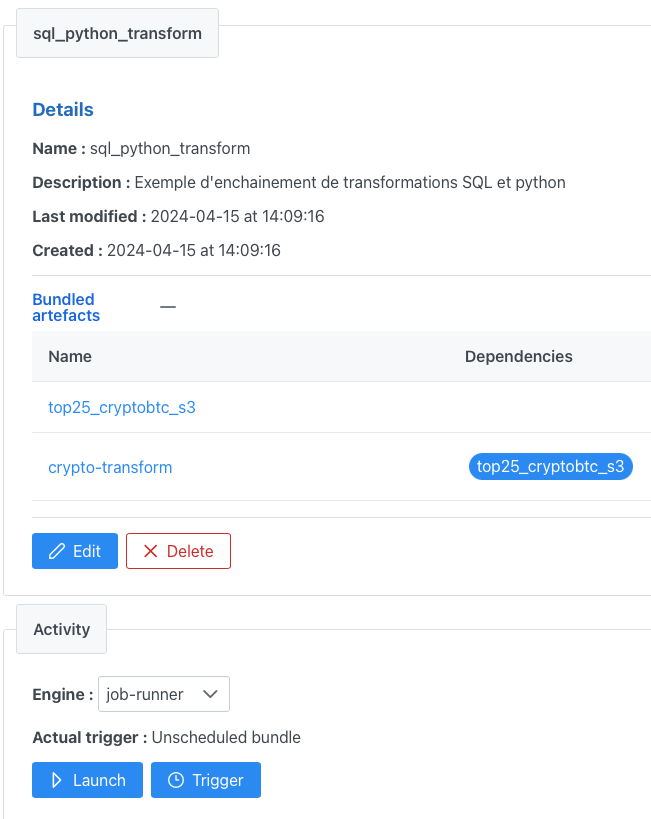
Ce mécanisme fonctionne très bien mais présente un inconvénient : la transformation python n’apparaît pas dans le lineage de la documentation DBT puisqu’elle ne fait pas partie du projet DBT.
Transformation par modèle DBT python
Dans le contexte du dalakehouse duckdb / S3 / DBT mis en place il est possible d’utiliser une autre solution qui consiste à définir un modèle DBT de type python qui utilisera l’environnement d’exécution DBT.
Pour cela, il suffit de créer un nouveau modèle dans le projet DBT en remplaçant le fichier SQL par un fichier python (par exemple my_python_model.py qui contient une fonction définie de la manière suivante :
import ...
def model(dbt, session):
my_sql_model_df = dbt.ref("my_sql_model")
final_df = ... # transformation qui ne peut pas être faite en SQL
return final_df
Note : les dépendances python doivent être disponibles dans l’environnement d’exécution DBT
Par exemple notre projet DBT permet de calculer, via des transformations SQL, un top 25 des cryptos sur la période 2023 (prix les plus élevés sur une journée).
Il est possible d’ajouter le prix moyen actuel (5 dernière minutes) via un appel api réalisé en python :
def get_avg_price(symbol):
import requests
base_url = "https://api.binance.com"
params = {"symbol": symbol}
try:
response = requests.get(f"{base_url}/api/v3/avgPrice", params=params)
response.raise_for_status()
return response.json()["price"]
except requests.exceptions.HTTPError as err:
return -99999
def model(dbt, session):
dbt.config(materialized="external")
dbt.config(
location="s3://crypto-histo/crypto/dbt-test/top25vscurrent.csv"
)
top25 = dbt.ref("top25_cryptobtc_s3")
final_df = top25.df()
final_df["avg_price"] = final_df["symbol"].apply(get_avg_price)
return final_df
Le résultat est ici matérialisé par un fichier csv dans le datalake top25vscurrent.csv
symbol,maxhigh,avg_price
RENBTCBTC,5.0,0.99388733
WBTCBTC,1.05,1.00099941
PAXGBTC,0.1168,0.03583000
MKRBTC,0.09073,0.04819856
AUTOBTC,0.03688,0.00327083
ILVBTC,0.0336,0.00158901
BNBBTC,0.0197,0.00876227
QUICKBTC,0.01895,0.00000092
FARMBTC,0.016876,0.00075097
COMPBTC,0.015358,0.00083504
ALCXBTC,0.014,0.00042928
GNOBTC,0.0133,0.00562398
BNXBTC,0.0122,0.00001188
QNTBTC,0.011865,0.00162744
AAVEBTC,0.0101,0.00134690
KSMBTC,0.009834,0.00048500
XMRBTC,0.009548,0.00228723
MOVRBTC,0.0095,0.00020060
MLNBTC,0.0075,0.00033254
DASHBTC,0.005928,0.00046018
ZECBTC,0.005182,0.00033730
DCRBTC,0.004326,0.00031599
GMXBTC,0.003999,0.00043500
CVXBTC,0.0037926,0.00008543
AXSBTC,0.003262,0.00011160
La documentation DBT accessible directement dans la plateforme datatask permet de visualiser le lineage de l’ensemble des transformations appliquées à la donnée :

Comme dans le cas précédent du script de transformation python “indépendant”, la mise en production peut être réalisée via la plateforme datatask.
Cette dernière permet également de définir la “taille” du runner qui va être utilisé pour l’environnement d’exécution DBT afin de prendre en charge une grande diversité de modèles tout en optimisant les coûts. Il est par exemple possible de configurer un runner “minimal” pour le traitement de l’exemple précédent ou un runner avec 32vCPU et 256Go de RAM pour des traitements plus lourds.
Conclusion
Tout au long de ce post, nous avons vu avec quelle simplicité la plateforme datatask permet de gérer les transformations au sein d’un datalake à moindre coût. Cette approche permet de rendre accessible des scenarii de transformation très divers à l’aide de SQL et python tout en maintenant une documentation unifiée du processus complet.