
Jusqu’à présent, dans notre série de billets, nous avons vu comment mettre en place un workflow complet sur la donnée comprenant des étapes de transformations et la création d’un dashboard. Nous allons maintenant voir plus en détail deux fonctionnalités de DBT qui vont nous permettre d’améliorer la gouvernance autour de la donnée :
- La création et l’execution de tests sur la donnée pour s’assurer de sa qualité
- La création d’
exposurequi va permettre de compléter la documentation en représentant le lineage complet depuis les sources de données dans le data warehouse, jusqu’au dashboard metabase en passant par les transformations de données DBT.
Les tests dans DBT
Définition
Dans DBT, il est possible de définir des tests aussi bien sur les sources de données que sur les modèles. Il existe 2 types de tests :
- “schema tests” : ce sont les plus basiques et faciles à mettre en oeuvre. Ils sont prédéfinis et configurés dans les fichiers yaml. Les tests existants à l’heure actuelle sont :
- unique
- not_null
- accepted_values
- relationships
Par exemple, sur le modèle events de datatask, je peux ajouter un test relationship qui vérifie que les sessionid de ce modèle sont présents dans le modèle sessions (foreign key) et un autre test qui vérifie que le champ eventtype ne contient que les valeurs [‘URLSHORT’,‘DATA’,‘CLICK’,‘REDIRECT’,’’] :
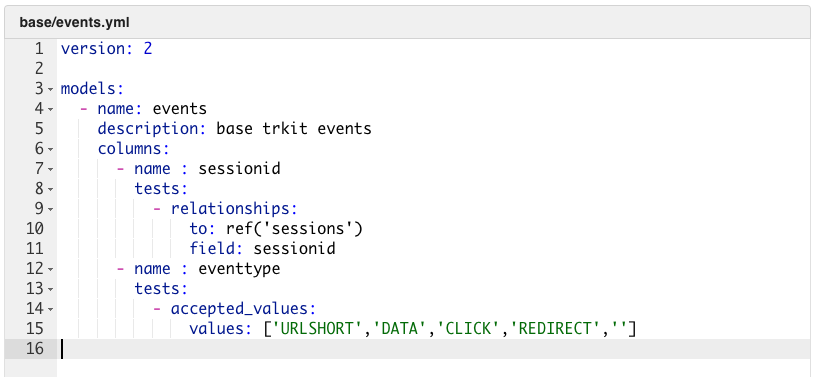
- “data tests” : ces sont des tests complètement configurables dans la mesure où ils reposent sur une requête SQL. Le test sera valide s’il retourne 0 ligne.
Par exemple, pour vérifier dans le modèle events que le champ trkitid est NULL uniquement lorsque l’event type est URLSHORT (URL shortener), on peut utiliser la requête suivante :
SELECT
trkitid
FROM
{{ ref('events') }}
WHERE
trkitid is NULL
AND eventtype != "URLSHORT"
Exécution
Une fois que les tests ont été définis, la commande pour exécuter les tests est la suivante : dbt test
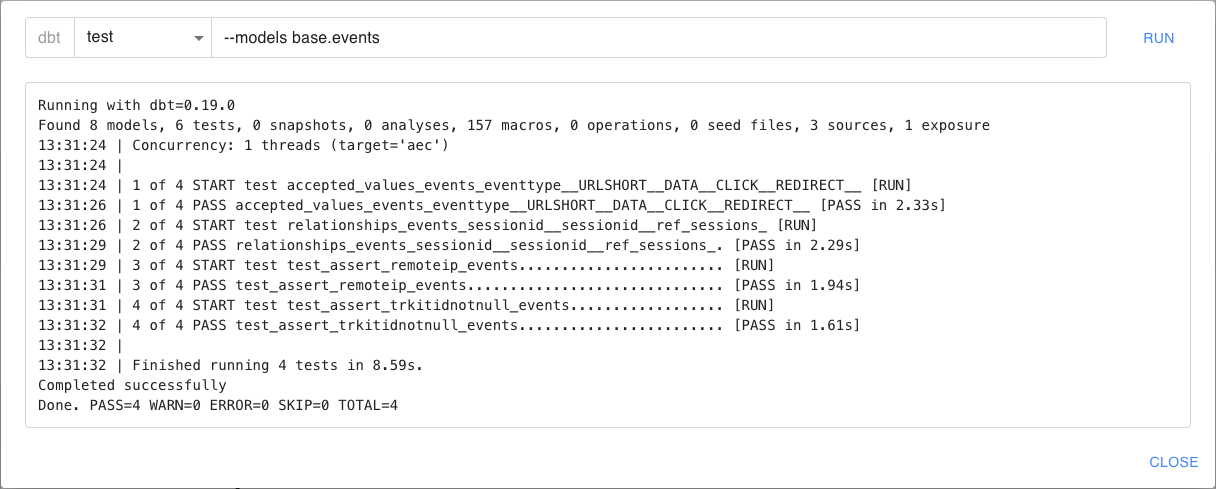
Il est possible de lancer les tests de manière ciblée avec le sélecteur “–models”. L’exemple suivant exécute l’ensemble des tests relatifs au model “events” et indique que tous sont passés avec succès :
Schema tests personnalisés et macros
Nous avons vu précédemment que les “schema tests” sont très faciles à utiliser car pré-définis. Cependant leur nombre est très limité et on est très vite amené à écrire des “data tests” pour répondre à des besoins spécifiques. En fait il est également possible d’écrire ses propres “schema tests” à l’aide de l’outil DBT “macros”. Les macros sont des fonctions réutilisables qui combinent le SQL avec le templating JINJA. Pour créer un nouveau “schema tests”, il suffit d’écrire une macro qui va retourner le nombre de lignes ne répondant pas à une condition. Si ce nombre est 0, le test sera valide.
On peut ajouter la macro suivante (test_not_emptystring.sql) pour créer un nouveau “schema test” qui vérifiera qu’une colonne de type string ne contient pas de chaine vide :
{% macro test_not_emptystring(model, column_name) %}
with validation as (
select
{{ column_name }} as string_field
from {{ model }}
),
validation_errors as (
select
string_field
from validation
where string_field = ""
)
select count(*)
from validation_errors
{% endmacro %}
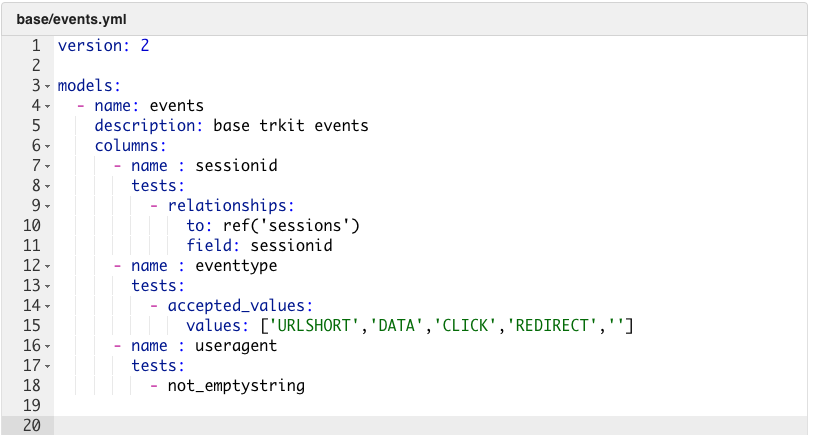
Ensuite pour appliquer ce test à la colonne useragent du modèle events, il faut éditer le fichier events.yml dans DataTask :
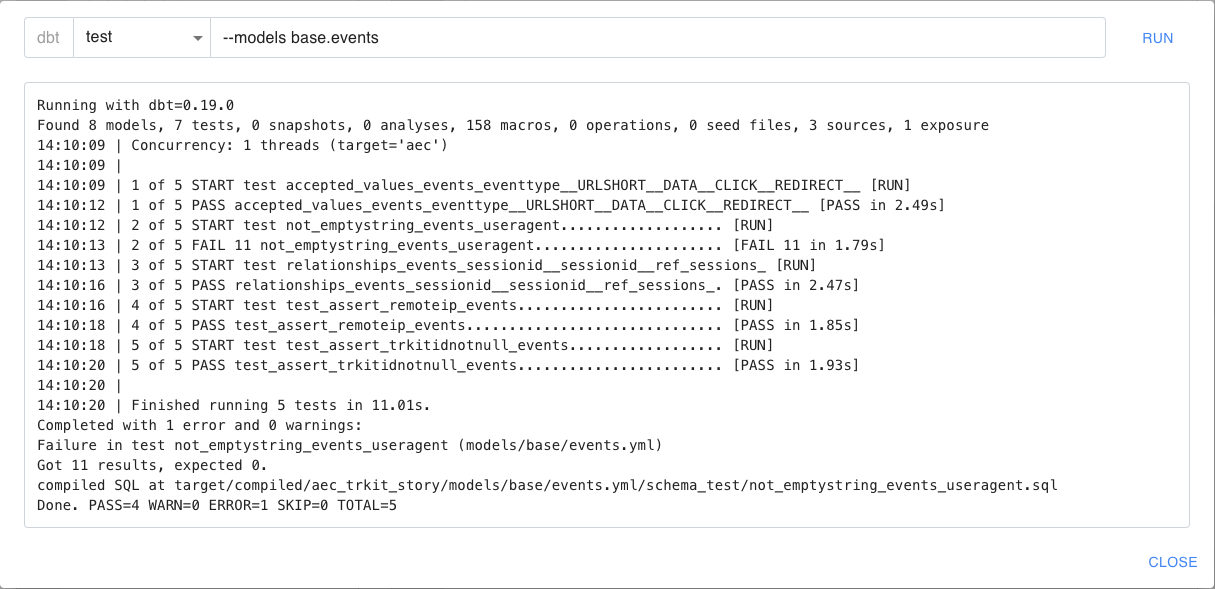
L’exécution des tests sur le modèle events montre que ce dernier ne passe pas (11 lignes contiennent des useragent="")
Exposures
Jusqu’à présent, nous avons vu qu’il était possible de générer automatiquement la documentation liée à l’ensemble des transformations réalisées au sein de DBT. Cette documentation nous permet, entre autres, d’avoir accès au lineage de transformations depuis les sources de données jusqu’aux tables finales qui vont être exploitées par des outils de reporting comme metabase. Les exposure vont nous permettre d’étendre cela en ajoutant le lien entre ces tables finales et les dashboards créés dans metabase.
La création et configuration d’une exposure se font à travers un fichier yaml :
version: 2
exposures:
- name: trkit_sessions
type: dashboard
maturity: low
url: https://apps.datatask.io/apps/metabase/dashboard/1?countryname=France
description: >
Overview of trkit sessions for France
depends_on:
- ref('sessions_final')
owner:
name: Laurent Couarraze
email: xxx@yyyy.zzz
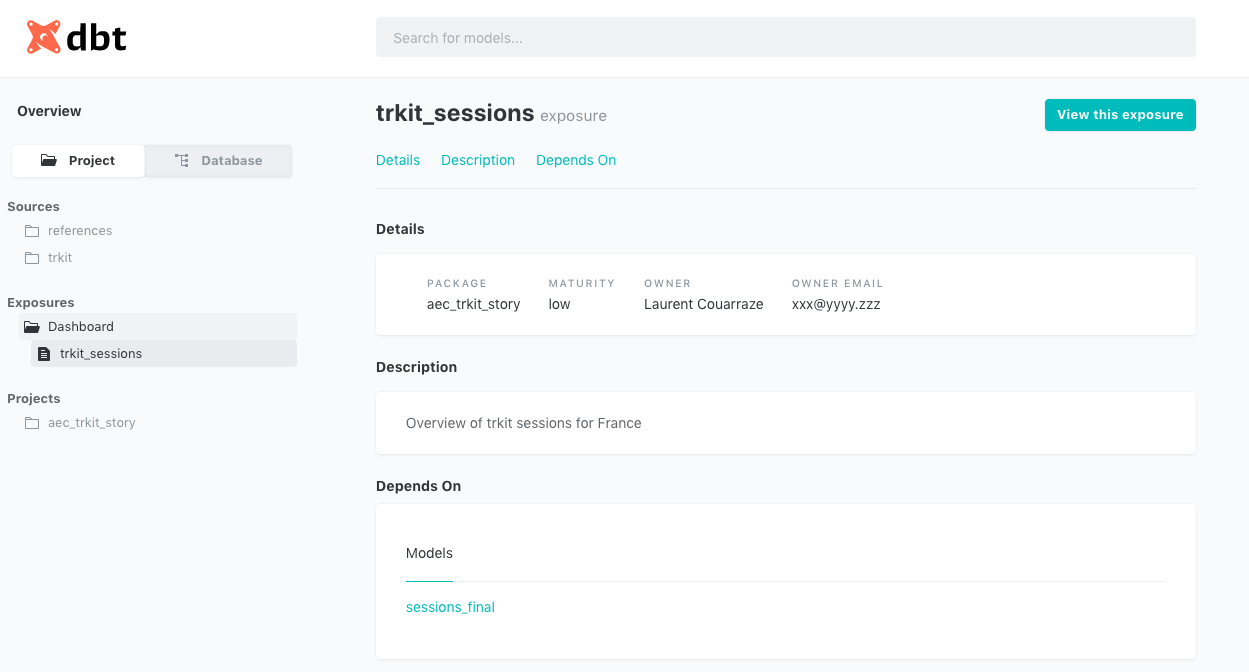
Le dashboard est maintenant documenté (et est accessible directement via le bouton “view this exposure”):
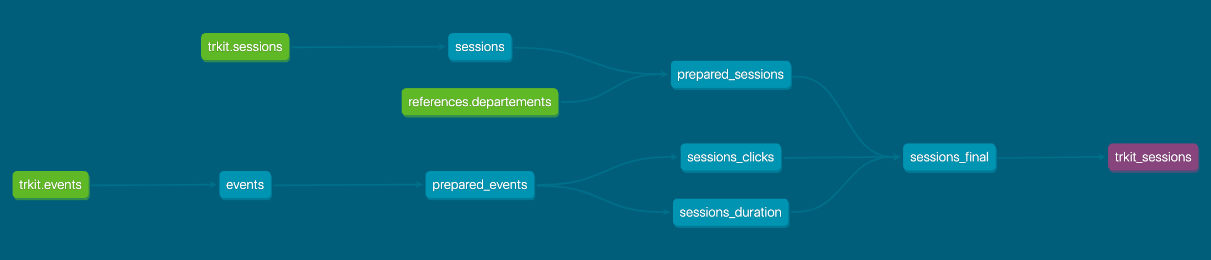
Ainsi que le lineage :
Conclusion
Nous avons mis en place, à travers les différents billets de cette série, un workflow complet de traitement de données ainsi que la documentation et les tests associés. Néanmoins, ce workflow est pour le moment déclenché manuellement à la demande. Pour assurer la mise à jour régulière des données, nous aborderons dans la dernière publication de cette série la mise en place d’un pipeline planifié au sein de DataTask. Cette dernière brique nous permettra donc d’avoir un worflow totalement automatisé.
Ce billet fait partie d’une série :
- DataTask pour construire une self-service BI
- Une revue des principaux concepts de dbt et création d’un premier modèle dans DataTask (ce billet)
- L’étude du workflow de transformation complet via DBT ainsi que la présentation de la documentation automatique associée
- Une revue rapide des principales fonctionnalités de Metabase, et plus particulièrement la création d’un dashboard d’analyse automatique, son édition et sa sauvegarde pour publication
- L’utilisation de fonctionnalités supplémentaires de DBT pour améliorer la gouvernance autour de la donnée : la création de tests sur la donnée et documentation de lineage à travers les exposures
- La mise en place d’un pipeline DataTask de manière à assurer la mise à jour automatique des données au cours du temps